Hadoop安装和启用
Hadoop简介
Hadoop是Apache软件基金会的一个开源分布式计算平台,主要由HDFS(分布式文件系统)、MapReduce(分布式计算框架)和YARN(资源管理系统)三个核心组件构成。它允许使用简单的编程模型在由多台计算机组成的大型集群上分布式处理大数据集。Hadoop具有高可靠性、高扩展性、高容错性和高效性等特点,已成为大数据处理的标准平台。
前提条件
在安装Hadoop之前,请确保:
- 已安装JDK(推荐JDK 8或更高版本)
- 配置了SSH无密码登录(对于集群环境)
- 分配了足够的系统资源(内存、存储空间)
环境配置
设置Hadoop环境变量
环境变量配置是使用Hadoop的第一步,它使系统能够找到Hadoop的可执行文件和库。
1 | # 编辑~/.bashrc或/etc/profile文件 |
说明:
HADOOP_HOME指向Hadoop的安装目录- 将Hadoop的bin和sbin目录添加到PATH中,使命令可以直接执行
- 根据实际安装路径调整
/soft/hadoop
Hadoop启动流程
1. 启动HDFS
HDFS(Hadoop分布式文件系统)是Hadoop的存储层,需要首先启动。
1 | # 在Hadoop的安装目录下执行 |
启动过程:
- 启动NameNode(主节点)
- 启动DataNode(数据节点)
- 启动Secondary NameNode(辅助名称节点)
验证HDFS启动成功:
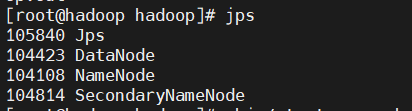
执行jps命令,应该能看到以下进程:
- NameNode
- DataNode
- SecondaryNameNode
也可以通过Web界面访问HDFS:http://localhost:9870
2. 启动YARN
YARN(Yet Another Resource Negotiator)是Hadoop的资源管理和作业调度系统。
1 | # 在Hadoop的安装目录下执行 |
启动过程:
- 启动ResourceManager(资源管理器)
- 启动NodeManager(节点管理器)
验证YARN启动成功:
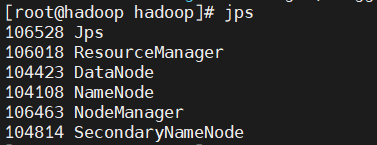
执行jps命令,应该能看到以下额外进程:
- ResourceManager
- NodeManager
可以通过Web界面访问YARN:http://localhost:8088
Spark与Hadoop集成
Apache Spark是一个快速的分布式计算框架,可以与Hadoop集成使用,利用HDFS存储数据,并通过YARN管理资源。
启动Spark
1 | # 在Spark的安装目录下执行 |
说明:
- 这将启动Spark的Master和Worker节点
- 如果配置了与YARN集成,Spark应用将通过YARN调度
验证Spark启动成功:
- 执行
jps命令,应该能看到Master和Worker进程 - 访问Spark Web UI:
http://localhost:8080
常用操作命令
HDFS文件操作
1 | # 查看HDFS根目录 |
YARN作业管理
1 | # 查看应用列表 |
故障排除
常见问题
启动失败:
- 检查日志文件(logs目录下)
- 确保端口未被占用
- 验证权限设置
节点未启动:
- 检查SSH配置
- 验证hosts文件配置
- 检查防火墙设置
Web界面无法访问:
- 确认服务已启动
- 检查网络连接
- 验证防火墙规则
完整启动流程
对于生产环境,建议按以下顺序启动Hadoop生态系统:
1 | # 1. 启动HDFS |
总结
正确配置和启动Hadoop是大数据处理的基础。通过本文的步骤,您应该能够成功设置Hadoop环境变量并启动Hadoop的核心服务(HDFS和YARN)以及Spark。记得定期检查日志文件以确保系统正常运行,并根据需要调整配置参数以优化性能。

